수학과 통계의 관계
내가 생각하는 수학과 통계에 대한 생각을 풀어놓은 글이다. 2020년에 ppt에 정리함으로써 위의 관계에 대해 생각해보았다. 전부터 자신이 이해한 방식대로 수학에서 중요한 부분들을 서술해보고자 했는데, 이번 기회에 한 번 서술해 보고자 한다.
내 생각의 결론은 다음과 같다.
간단하게 uncertainty(불확실성)를 독립적으로 더했지만, 단순하게 표현하기 위함이다. 위와 같이 Linear 한 성질이 아니라 내재되어 있는 Non-linear 성질일지도 모른다. 그리고 난 수학을 통계에 포함된다고 보았고, 통계에서 Averaged 된 값을 가지고 Deterministic 하게 다루는 것이라 보았다.
1. 수학에서 문제를 푼다는 것은?
우리가 현실 또는 가상에서 접하는 문제(물리적 문제)를 수학적으로 정의된 실제 공간(Real space) 이든 가상 공간(Complex space) 이든 그 위에 점, 직선, 곡선, 평면, 곡면, 또는 부피 등의 조합으로 표현이 가능하며, 공간상 표현된 수식(물리적 문제)에 대해 연산을 통하여 조정하고 연산하여 원하는 값(의미적으로 원하는 현상)을 얻어내는 것을 의미한다.
즉, 우리가 원하는 어떤 현상 \(g(x,y,z,t)\) 를 또 다른 수학적 표현 \(f(x,y,z,t)\) 로 옮겨 다루는 것이 수학인 셈이다.
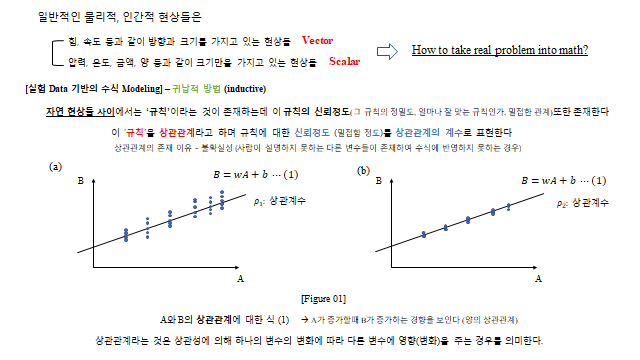
2. 현상의 분류 — Vector와 Scalar
일반적인 물리적, 인간적 현상은 힘, 속도 등과 같이 방향과 크기를 가지고 있는 현상을 Vector, 압력, 온도, 금액, 양 등과 같이 크기만을 가지고 있는 현상을 Scalar 라 한다. 그렇다면 이런 실제 문제를 어떻게 수학으로 가져올 것인가(How to take a real problem into math?) 가 출발점이 된다.
3. 실험 데이터 기반의 수식 모델링 (귀납적 방법)
[실험 Data 기반의 수식 Modeling] – 귀납적 방법(inductive) 이다. 자연 현상들 사이에서는 ‘규칙’이라는 것이 존재하는데, 이 규칙의 신뢰도(그 규칙의 정밀도, 얼마나 잘 맞는 규칙인가, 밀접한 관계) 또한 존재한다. 이 ‘규칙’을 상관관계 라 하며, 규칙에 대한 신뢰도(밀접한 정도)를 상관관계의 계수 로 표현한다.
상관관계의 존재 이유는 곧 불확실성 이다. (사회가 설명하지 못하는 다른 변수들이 존재하여 수식에 반영하지 못하는 경우다.) 두 변수 \(A,B\) 의 상관관계는 보통 다음 선형식으로 나타낸다.
위 [Figure 01] 의 (a), (b) 처럼 \(A\) 가 증가함에 \(B\) 가 증가하는 경향을 보인다(양의 상관관계). 즉 상관관계라는 것은 상관성에 의해 하나의 변수의 변화에 따라 다른 변수로 영향(변화)을 주는 경우 를 의미한다.
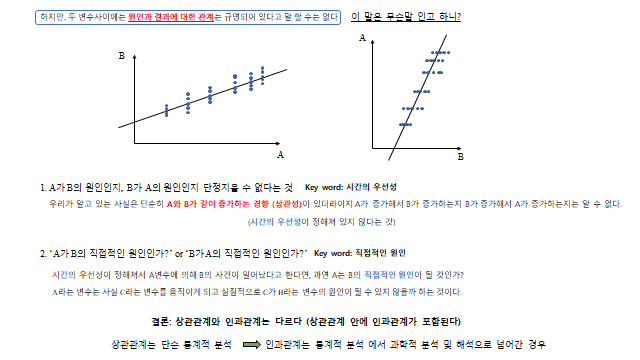
4. 상관관계 ≠ 인과관계
하지만, 두 변수 사이에는 원인과 결과에 대한 관계가 규명되어 있다고 말할 수 없다. 이 말은 무슨 말을 하고 하나? 두 가지로 나눠 보자.
① A가 B의 원인인지, B가 A의 원인인지 단정지을 수 없다 (Key word: 시간의 우선성)
우리가 알고 있는 사실은 단순히 \(A\) 와 \(B\) 가 같이 증가하는 경향(상관성)이 있다라는 것이지, \(A\) 가 증가해서 \(B\) 가 증가하는지 \(B\) 가 증가해서 \(A\) 가 증가하는지는 알 수 없다(시간의 우선성이 정해져 있지 않는 것).
② ‘A가 B의 직접적인 원인인가?’ or ‘B가 A의 직접적인 원인인가?’ (Key word: 직접적인 원인)
시간의 우선성이 정해져 \(A\) 에 의해 \(B\) 의 사건이 일어난다고 한다면, 과연 \(A\) 는 \(B\) 의 직접적인 원인이 될 것인가? \(A\) 라는 변수는 사실 \(C\) 라는 변수를 움직이게 되고, 실질적으로 \(C\) 가 \(B\) 라는 변수의 원인이 될 수 있지 않을까 하는 것이다.
결론: 상관관계와 인과관계는 다르다 (상관관계 안에 인과관계가 포함된다). 상관관계는 단순 통계적 분석 이고, 인과관계는 통계적 분석에서 과학적 분석과 해석으로 넘어간 경우 다.
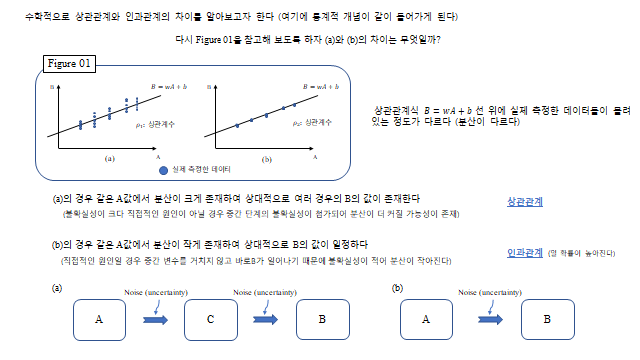
5. 수학적으로 본 두 관계의 차이 = 분산
수학적으로 상관관계와 인과관계의 차이를 알아보고자 한다(여기에 통계적 개념이 같이 들어가게 된다). 다시 [Figure 01] 을 참고해 보도록 하자. (a)와 (b)의 차이는 무엇일까? 바로 상관관계식 \(B=wA+b\) 선 위에 실제 측정한 데이터들이 흩어져 있는 정도가 다르다(분산이 다르다) 는 것이다.
(a)의 경우 같은 \(A\) 값에서 분산이 크게 존재하여 상대적으로 여러 경우의 \(B\) 의 값이 존재한다(불확실성이 크다. 직접적인 원인이 아닌 경우 중간 단계의 불확실성이 첨가되어 분산이 더 커질 가능성이 존재한다). (b)의 경우 같은 \(A\) 값에서 분산이 작게 존재하여 상대적으로 \(B\) 의 값이 일정하다(직접적인 원인일 경우 중간 변수를 거치지 않고 바로 \(B\) 가 일어나기 때문에 불확실성이 적어 분산이 작아진다).
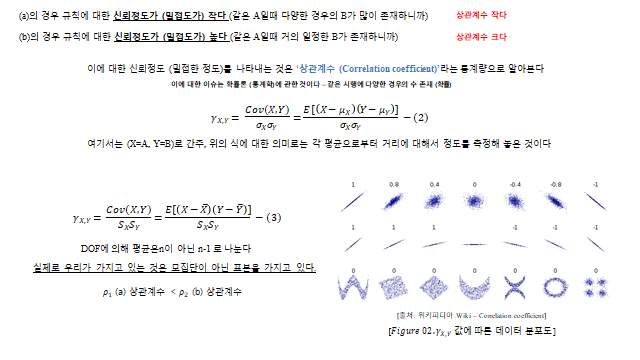
6. 신뢰 정도의 척도 — 상관계수
(a)의 경우 규칙에 대한 신뢰정도(일정정도)가 작고(같은 \(A\) 일 때 다양한 경우의 \(B\) 가 많이 존재하니까 → 상관계수 작다), (b)의 경우 규칙에 대한 신뢰정도가 높다(같은 \(A\) 일 때 거의 일정한 \(B\) 가 존재하니까 → 상관계수 크다). 이에 대한 신뢰정도(일정한 정도)를 나타내는 것은 ‘상관계수(Correlation coefficient)’ 라는 통계량으로 알아본다.
여기서는 \((X=A,\ Y=B)\) 로 간주한다. 위의 식에 대한 의미는 각 평균으로부터의 거리에 대해서 정도를 측정해 놓은 것 이다. 그리고 실제로 우리가 가지고 있는 것은 모집단이 아닌 표본 을 가지고 있으므로, DOF(자유도)에 의해 평균은 \(n\) 이 아닌 \(n-1\) 로 나눈다.
즉 (a)의 상관계수 \(\rho_1\) 보다 (b)의 상관계수 \(\rho_2\) 가 크다 \((\rho_1 < \rho_2)\).
7. 수학과 통계학의 연결지점 — 평균(average)
위에서 내릴 결론은, 상관관계(관계의 여부)가 있어도 상관계수(관계의 일정도)에 따라 그 상관관계식에 대한 신뢰도는 달라진다는 것이다(실제로 그 상관관계식을 믿어야 할지에 대한 여부).
여기서 \(A, B\) 는 실제로는 확률변수(Random variable) 이다. 이는 본질적으로 분포를 갖는 Stochastic 한 문제 다. 그런데 Deterministic 한 상관관계식을 어떻게 세울까? 분포를 갖는다면 우리는 이 불확실성을 정량화시켜 판단하는 통계학이 들어갈 수밖에 없다. 그리고 우리는 보통 모수 통계학 을 기반으로 가정하는데, 모수-통계학에서는 모집단은 Gaussian distribution 을 갖는다고 가정을 한다.
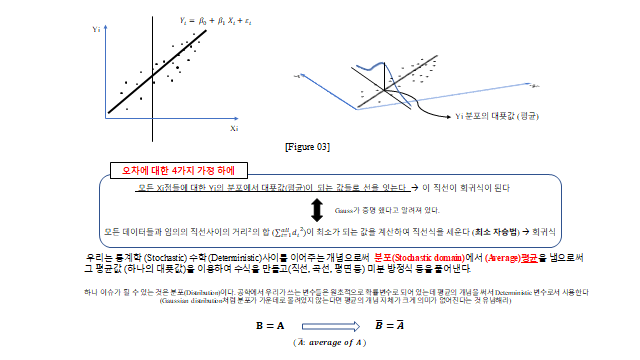
그리고 하나의 Deterministic 한 상관관계식을 세우기 위해 ‘Least square method’ 를 이용하여 관계식 – (회귀식)을 세운다. 이때 오차에 대한 4가지 가정(가우스-마코프 가정) 이 따라온다.
- 임의의 주어진 \(X_i\) 값에 대한 오차 \(\varepsilon_i\) 의 평균 \(E(\varepsilon_i)=0\) 이다.
- 모든 \(X_i\) 값에 대한 오차의 분산 \(\mathrm{Var}(\varepsilon_i)=\sigma^2\) 으로 일정하다 (등분산).
- 오차 \(\varepsilon_i\) 는 정규성 Normality 를 따른다.
- 각 오차들 간에는 독립적이다. \(\big(\varepsilon_i \overset{iid}{\sim} N(0,\sigma^2)\big)\)
이때 동시에 모집단의 상관관계식에서의 오차에 대한 가정들이 맞아야 상관관계식의 신뢰도가 보증된다.
8. 회귀식과 최소자승법
오차에 대한 4가지 가정 하에서, 모든 \(X_i\) 들마다에 대한 모든 \(Y_i\) 의 분포에서 대푯값(평균)이 이루는 값들을 선으로 이을 수 있는데, 이 직선이 회귀식이 된다. 동시에 모든 데이터들과 임의의 직선 사이의 거리의 합 \(\big(\sum d_i^2\big)\) 이 최소가 되는 값을 계산하여 직선식을 세운다(최소 자승법).
우리는 통계학(Stochastic)과 수학(Deterministic) 사이를 이어주는 개념으로써, 분포(Stochastic domain)에서 평균(Average)을 넘음으로써 그 평균값(하나의 대푯값)을 이용하여 수식을 만들고(직선, 곡선, 평면 등) 미분 방정식 등을 풀어낸다.
하나 이슈가 될 수 있는 것은 분포(Distribution)이다. 왜냐하면 \(y\) 값이라는 것이 어느 정도의 분포를 가지고 있는데, 이를 하나의 대푯값으로써 평균의 개념을 써서 Deterministic 한 변수로서 사용하기 때문이다.
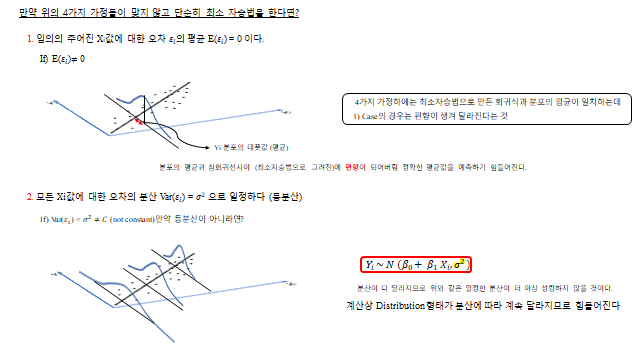
9. 만약 4가지 가정이 맞지 않는다면?
만약 위의 4가지 가정들이 맞지 않고 단순히 최소 자승법을 한다면 어떻게 될까? 하나씩 보자.
- ① \(E(\varepsilon_i)\neq 0\) 이면 — 4가지 가정 하에서는 최소자승법으로 만든 회귀식과 분포의 평균이 일치하는데, 이 경우는 편향이 생겨 달라진다. 분포의 평균과 회귀곡선식(최소자승법으로 그려진)이 편향이 되어버려 정확한 평균값을 예측하기 힘들어진다.
- ② \(\mathrm{Var}(\varepsilon_i)=\sigma^2 \neq C\) (등분산이 아니라면) — \(Y_i \sim N(\beta_0+\beta_1 X_i,\ \sigma^2)\) 에서 분산이 더 달라지므로 위와 같은 일정한 분산은 더 이상 성립하지 않을 것이다. 계산상 Distribution 형태가 분산에 따라 계속 달라지므로 힘들어진다.
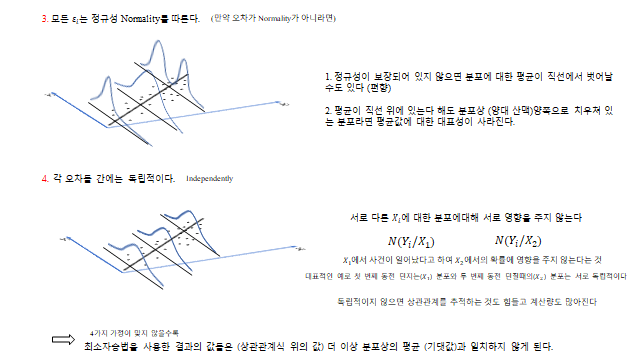
- ③ 정규성(Normality)을 따르지 않으면 — (1) 정규성이 보장되어 있지 않으면 분포에 대한 평균이 직선에서 벗어날 수도 있다(편향). (2) 평균이 직선 위에 있다 해도 분포상 양쪽으로 치우쳐 있는 분포라면 평균값에 대한 대표성이 사라진다.
- ④ 각 오차가 독립적이지 않으면 — 서로 다른 \(X_i\) 에 대한 분포가 서로 영향을 주게 된다(\(N(Y_i\mid X_1),\ N(Y_i\mid X_2)\)). 독립적이지 않으면 상관관계를 추적하는 것도 힘들고 계산량도 많아진다.
→ 즉, 4가지 가정이 맞지 않을수록 최소자승법을 사용한 결과의 값들(상관관계식 위의 값)은 더 이상 분포상의 평균(기댓값)과 일치하지 않게 된다.
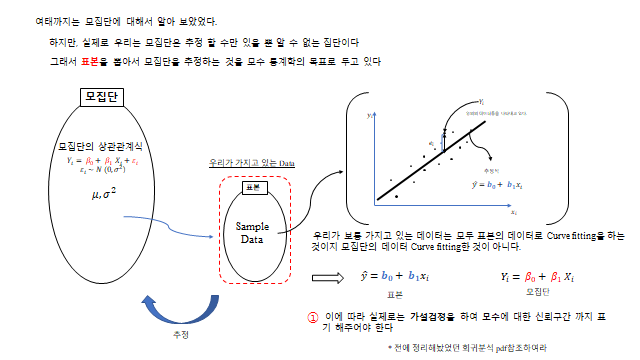
10. 모집단 vs 표본
여태까지는 모집단에 대해서 알아 보았다. 하지만, 실제로 우리는 모집단은 추정 할 수만 있을 뿐 알 수 없는 집단 이다. 그래서 표본을 뽑아서 모집단을 추정하는 것을 모수 통계학의 목표 로 두고 있다.
우리가 보통 가지고 있는 데이터는 모두 표본의 데이터로 Curve fitting 을 하는 것이지 모집단의 데이터로 Curve fitting 하는 것이 아니다(표본: \(\hat y = b_0 + b_1 x_i\), 모집단: \(Y_i = \beta_0 + \beta_1 X_i\)). ① 이에 따라 가설검정을 하여 모수에 대한 신뢰구간까지 표기해 주어야 한다.
11. 잔차로 4가지 가정을 확인
② 그리고 모집단에서 상관관계식을 만들 때 사용되었던 오차에 대한 4가지 가정이 잔차에서도 성립하는지 확인해야 한다. 앞에서 (4가지 가정 하에) 모집단에서의 상관관계식의 특징은 ‘각 분포의 평균값 = 상관관계의 값’ 이었다. 우리는 확률적인 요소를 하나의 대푯값으로써 Deterministic 하게 사용하고 싶은 것이다.
그런데 오차에 대한 개념은 모집단의 상관관계식(모수)과 실제 값의 차이이기 때문에 우리는 알 수 없다. 이 때문에 우리가 가지고 있는 것은 표본이고, 실제로 측정 가능한 것은 잔차 이므로 잔차에 대한 평균을 구해 보는 것이다. 잔차는 오차에 대한 최상의 정보를 제공하고 있다. 데이터를 가지고 상관관계식을 세울 때 세부적으로 봐야 할 순서는 다음과 같다(무작정 Least square method 로 수식 세우고 끝내는 게 아니다).
- 상관관계가 존재하는지 확인한다.
- Least square method 를 사용하여 상관관계식을 얻는다.
- 표본에 대한 상관식이기에 모수 추정을 하여 신뢰구간을 표시해보자.
- 잔차에 대해 앞서 알아본 오차에 대한 4가지 가정이 잘 맞는지 확인해야 한다. (과연 평균을 통하여 Deterministic 하게 표현을 해도 유효한가? — 평균에 대한 신뢰도를 알아보기 위함)
- 각 \(X_i\) 값에 대한 \(Y_i\) 의 분산(표준편차)에 대해서도 확인해야 한다 (상관계수).
12. 정리 (Summary)
표본(Sample)에서, 평균(Average) 을 통해 Stochastic 을 Deterministic 으로 넘긴다.
“\(y = f(x)\) Deterministic equation 이 Stochastic 의 \(Y=f(x)\) 식을 충분히 대표할 수 있을까?” 를 확인하려면:
- Check A. 잔차에 대해 앞서 알아본 오차에 대한 4가지 가정이 잘 맞는지 확인 → 정확도
- Check B. 각 \(X_i\) 값에 대한 \(Y_i\) 의 분산(표준편차)도 확인 (상관계수) → 정밀도
- Check C. 표본에 대한 상관식이기에 모수 추정을 하여 신뢰구간을 표시
그렇게 모집단(Universe) \(Y_i=\beta_0+\beta_1 X_i\) 로 향한다. 이것이 곧 통계식에서 수학식으로 넘어가는 과정(불확실성을 처리하는 방법) 이다.
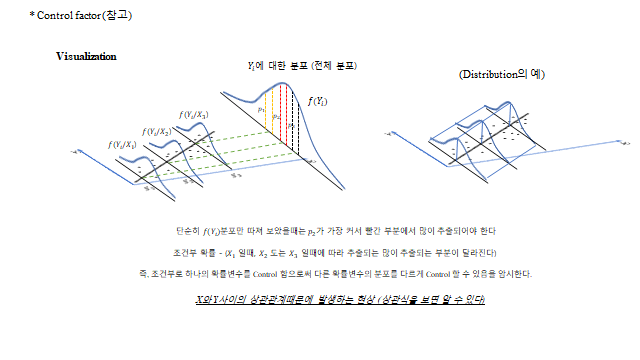
참고 ① Control factor
전체 분포 \(f(Y_i)\) 만 따져 보았을 때는 \(p_2\) 가 가장 커서 빨간 부분에서 많이 추출되어야 한다. 그런데 조건부 확률 — \(X_1\) 일 때, \(X_2\) 또는 \(X_3\) 일 때 \(f(Y_i\mid X_k)\) — 에 따라 많이 추출되는 부분이 달라진다. 즉, 조건부로 하나의 확률변수를 Control 함으로써 다른 확률변수의 분포를 다르게 Control 할 수 있음을 암시한다. 이것이 \(X\) 와 \(Y\) 사이의 상관관계 때문에 발생하는 현상이다(상관식을 보면 알 수 있다).
참고 ② 과학적 사고의 수식 모델링 — 연역적 방법(deductive)
위가 귀납적 방법이었다면, [과학적 사고의 수식 Modeling] – 연역적 방법(deductive) 도 있다. 열역학, 유체역학, 고체역학, 동역학 등에서 과학적 현상을 기반으로(법칙 등을 믿고) 모델링하는 경우가 이에 해당된다. 모델링부터 Deterministic 하게 작동한다고 가정하기 때문에(일정 Error 를 믿고 시작한다), Homogeneous · 1-Dimensional · Isotropic 등의 가정이 이에 해당된다.
- 열역학 — 하나의 System 을 보기 때문에 Control volume, System 단위 Equation 을 만드는 경우가 많다.
- 고체역학 — Torsion, Tension, Compression, Bending 등 Differential(element) 단위에서 시작해서 전체로 합치는 경우가 많다 (Stress point 개념을 주로 쓰기 때문에).
- 동역학 — Material 의 한 지점에 대한 응력을 계산하는 것이 아닌, (Kinetics & Kinematics) \(F=ma\) 를 기반으로 Motion 에 대해 알아보기 때문에 이 또한 System 단위로 보는 경우가 많다.
- 유체역학 — Control volume, System 단위로 보는 경우(Reynolds Transport theorem)와 Differential(element) 단위로 보는 경우(Navier–Stokes equation)가 다 존재한다.
Motion 을 알아볼 때 기반이 되는 관계식은 \(F=ma\), Energy 에 대한 Equation 은 Energy conservation 이다(운동량 보존법칙, 열역학 제2법칙(엔트로피) 등도 존재). 위 두 식이 거의 관계식의 시작점이 된다. 시작점부터 Stochastic 한 수식에서 넘어온 Deterministic 한 수식을 사용하는 셈이다.
위의 경우는 불확실성 요소를 다루기 위한 하나의 방법을 제시한 것뿐이다. 위에서 통계학의 개념과 수학의 개념을 이은 방법은 적률법(Moment method) 이라는 전통통계학적인 방법으로 보여 준 것이다. 위의 전통적인 Moment method estimate 말고도 MLE(Maximum Likelihood Estimate) 또한 존재한다.
원본 PPT 슬라이드 보기






📑 위 슬라이드는 제가 대학원 시절 수학과 통계의 관계를 직접 고민하고 정리한 자료입니다.