머신러닝 기초 (Fundamentals of ML)
머신러닝을 수학·통계의 관점에서 바닥부터 정리한 글이다. 큰 줄기는 셋 — ① 회귀로 보는 학습의 원리(선형회귀 → 손실함수 → 경사하강) → ② 분류(시그모이드 → 교차엔트로피 → 다중분류·소프트맥스) → ③ 학습을 잘 시키는 법(학습률 · 정규화 · 과적합).
한 줄 정의 — 머신러닝은 여러 데이터를 목적에 맞게 스스로 분류(Classification) 하거나 수치를 예측(Extrapolation) 하는 시스템이다. 핵심은 “모델의 오차(Loss)를 가장 작게 만드는 파라미터를 찾는 것” 하나로 수렴한다.
1. 머신러닝이란?
머신러닝이란 기계적으로 여러 데이터를 목적에 맞게 스스로 분류(Classification) 하거나 수치를 예측(Extrapolation) 하는 시스템을 구축하는 것을 의미한다. 더 나아가 자기 자신이 환경을 판단하고 사람이 원하는 행동을 할 수 있게 하는 것을 목표로 한다. 학습 방식(3 Types)에 따라 크게 셋으로 나뉜다.
- Supervised Learning (지도학습) — 정답(label)이 있는 데이터로 학습
- Unsupervised Learning (비지도학습) — 정답 없이 구조·군집을 학습
- Reinforcement Learning (강화학습) — 보상으로 행동을 학습
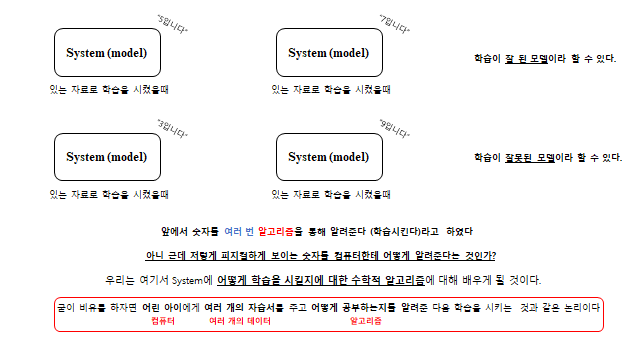
우선 가장 기본이 되는 Supervised Learning(지도학습)부터 알아보자. 지도학습에 대한 예시는 대표적으로 고양이 그림, 숫자 등을 학습시킨다는 것이 있다. 컴퓨터에게 숫자(0~9)에 대해서 여러 번 알고리즘을 통해 “이건 8이구나”, “이건 7이구나” 라고 알려준다(데이터 개수만큼). 그 다음 컴퓨터한테 임의의 숫자를 주어 test 를 해 보는 것이다.
있는 자료로 학습을 시켰을 때 잘 맞히면 학습이 잘 된 모델, 못 맞히면 학습이 잘못된 모델 이라 할 수 있다. 학습이 잘못된 모델의 경우 크게 이유가 두 가지 있다 — ① 공부를 아무리 열심히 해도 학습을 하는 자습서(데이터) 자체가 잘못된 내용 이면 학습이 잘 될 수 없다. ② 또한 공부법(알고리즘)이 잘못 되면 학습이 잘 될 수가 없다. 우리는 여기서 System(model)에 어떻게 학습을 시킬지에 대한 수학적 알고리즘을 배우게 될 것이다. 굳이 비유를 하자면, 어린 아이에게 여러 개의 자습서를 주고 어떻게 공부하는지를 알려준 다음 학습을 시키는 것과 같은 논리이다.
2. 선형 회귀 (Linear Regression)
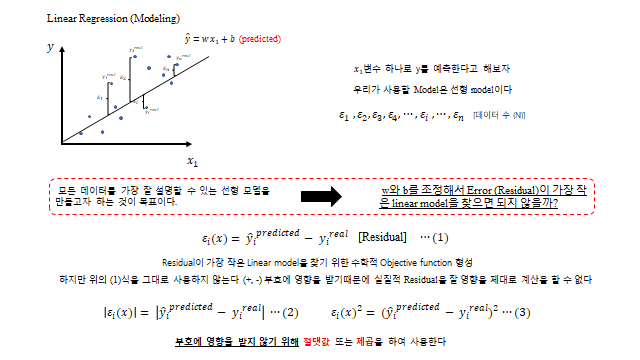
Machine learning 의 대표적인 목적 중 하나는 Extrapolation(예측) 이라 하였다. 우리가 수치해석이나 통계학에서 배웠을 때 예측하는 대표적인 model 이 무엇이 있을까? 바로 선형 회귀(Linear Regression, Curve fitting) 다. 여기서 \(x_1\) 은 설명 변수, \(y\) 는 타깃 변수다. 즉 \(y\) 에 대한 것을 \(x_1\) 변수와의 상관관계 를 통해서 예측해 보겠다는 것을 의미한다.
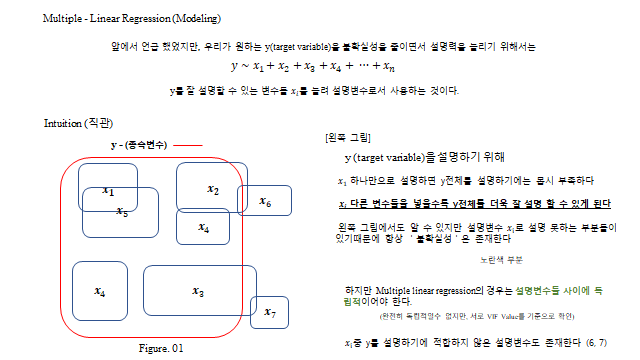
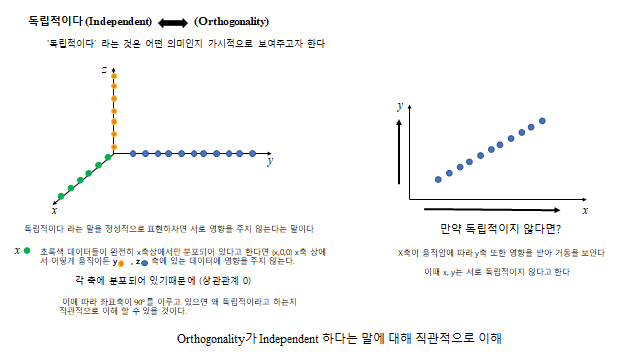
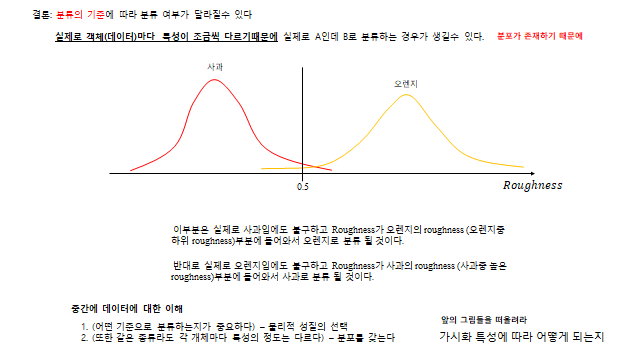
참고로, \(x_1\) 변수 하나만으로 \(y\) 를 완벽하게 설명하기는 힘들다(추가적인 변수가 필요한 것으로 보인다). \(x_1\) 으로 설명할 수 없는 부분들이 생기고, 이것에 의해 결과값 분포가 생긴다 — 이 설명하지 못하는 부분을 ‘불확실성’ 이라 한다. 따라서 서로 독립적인 설명변수가 늘어날수록 불확실성은 작아진다.
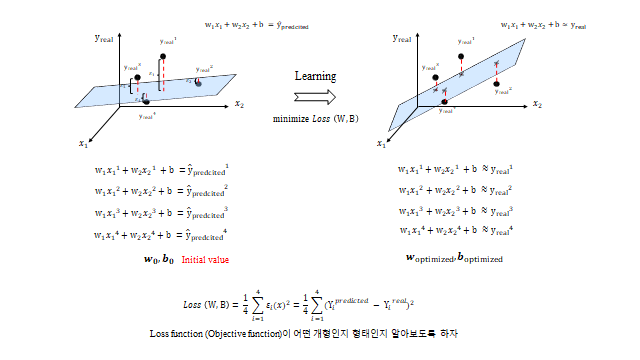
모든 데이터를 가장 잘 설명할 수 있는 선형 모델을 만드는 것이 목표다. → \(w\) 와 \(b\) 를 조정해서 Error(Residual) 이 가장 작은 linear model 을 찾으면 되지 않을까? 각 데이터의 잔차는 다음과 같다.
하지만 위의 (1)식을 그대로 쓰지는 않는다. \((+,-)\) 부호의 영향을 받기 때문에 실질적인 Residual 을 제대로 계산할 수 없기 때문이다. 그래서 부호에 영향을 받지 않기 위해 절댓값 또는 제곱 을 하여 사용한다.
그 중에서도 (3) 제곱 에 대한 식을 사용한다. Residual 의 차이가 클 때 더 크게 만들어 영향력을 키우고(잔차를 잡기 위해), 작으면 그 영향력은 줄이도록 하기 위함이다.
3. 손실 함수 (Loss / MSE)
그리고 하나의 대표값으로, 모든 데이터에 (3)식의 평균 을 낸다. 이것이 평균제곱오차(Mean square of error, MSE) 다.
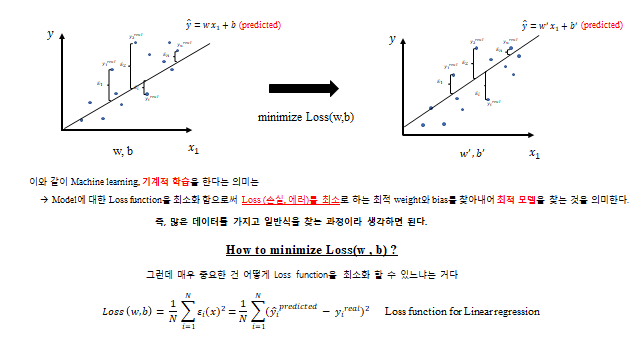
(4)식은 현재 모든 실제값과 그에 대한 예측모델의 예측값의 차이(잔차)를 고려한 Function 이다. 즉 위의 (4)식은 그 예측모델에 대한 Error(틀림) 정도 를 나타낸다. 따라서 어떤 모델에 대한 틀림 정도를 나타내는 지표로써, 이 함수를 Loss function / Cost function 이라 부른다.
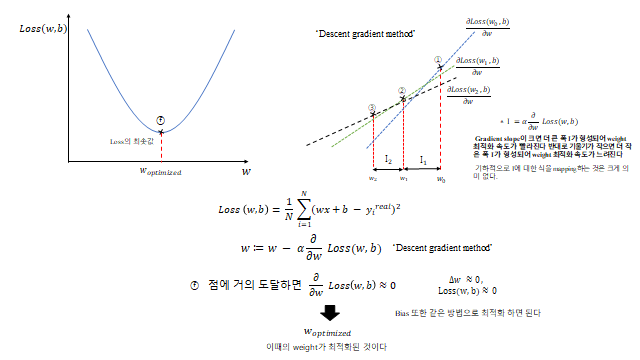
결국 위의 Loss function 을 수학적으로 풀어 error 가 가장 작은 \(w\)(weight), \(b\)(bias) 를 구하는 것이 곧 Model 이 학습 데이터에 fitting 이 가장 잘 되어 error 가 작은 model 이 되는 것이다. 즉 머신러닝(기계적 학습)을 한다는 의미는 — Model 에 대한 Loss function 을 최소화함으로써 Loss(손실·에러)를 최소로 하는 최적 weight 와 bias 를 찾아내어 최적 모델을 찾는 것 을 의미한다. 많은 데이터를 가지고 일반식을 찾는 과정이라 생각하면 된다.
4. 경사하강법 (Gradient Descent)
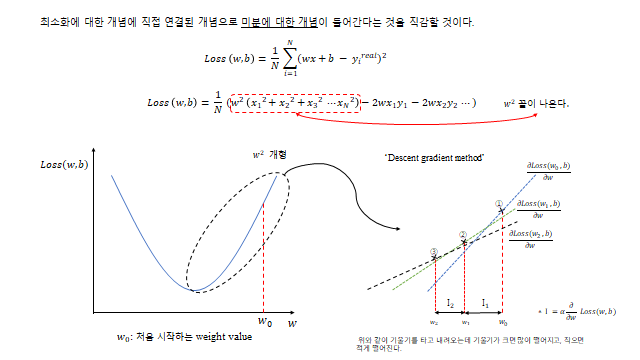
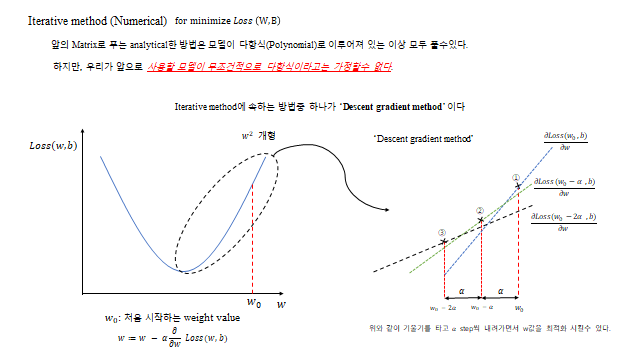
그렇다면 Loss 를 어떻게 최소화할까? 최소화에 대한 개념은 미분에 대한 개념과 직접 연결 된다. Loss 를 전개해 보면
처럼 \(w^2\) 꼴(아래로 볼록)이 나온다. 그래서 기울기를 따라 내려가면 최솟값에 도달한다 — ‘Descent gradient method’. \(w_0\) 는 처음 시작하는 weight value 이고, gradient slope(기울기)이 크면 더 큰 폭으로 움직여 weight 최적화 속도가 빠르고, 기울기가 작으면 최적화 속도가 느리다.
점에 거의 도달하면 \(\partial \text{Loss}/\partial w \approx 0\) 이 되고(\(\Delta w \approx 0\)), 이때의 weight 가 최적화된 \(w_{opt}\) 이다. bias \(b\) 또한 같은 방법으로 최적화한다.
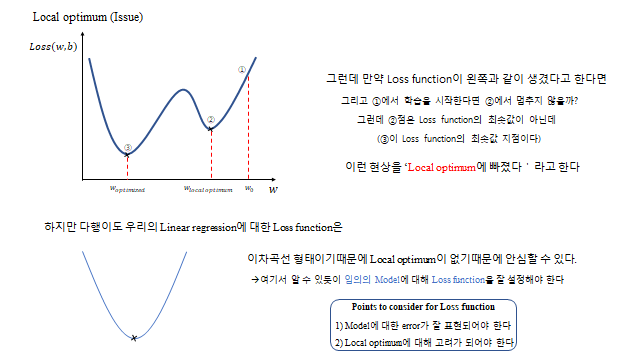
5. Local optimum 문제
그런데 만약 Loss function 이 여러 골짜기를 갖도록 생겼다면, 어떤 지점 ③ 에서 학습을 시작했을 때 ③ 에서 멈추지 않을까? ③ 점은 Loss function 의 최소값이 아닌데(다른 골짜기 ② 가 진짜 최소값 지점이다). 이런 현상을 ‘Local optimum 에 빠졌다’ 고 한다.
하지만 다행히도 우리의 Linear regression 에 대한 Loss function 은 이차곡선 형태 이기 때문에 local optimum 이 없어 안심할 수 있다. 여기서 알 수 있듯이 임의의 Model 에 대해 Loss function 을 잘 설정해야 한다 — ① 모델에 대한 error 가 잘 표현되어야 하고, ② local optimum 에 대한 고려가 되어야 한다.
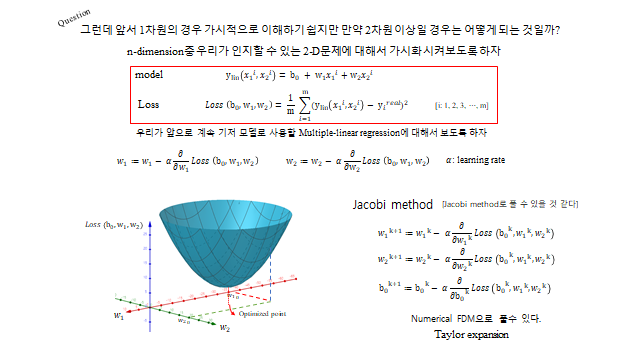
6. 다중 선형 회귀 (Multiple Linear Regression)
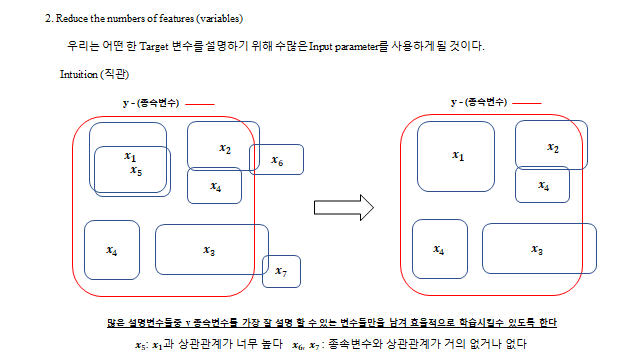
설명력을 높이려면 설명변수를 늘린다. 단, 변수들은 서로 독립(orthogonal) 이어야 한다(중복 정보 방지, VIF 로 점검).
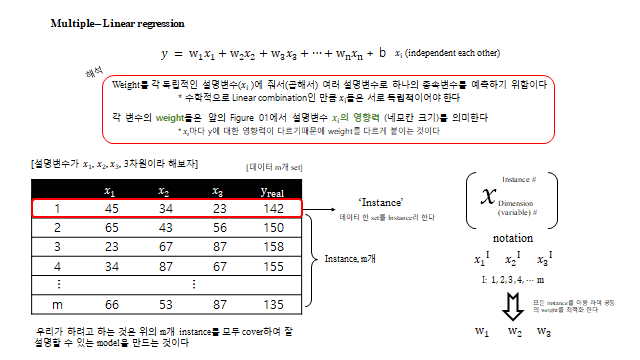
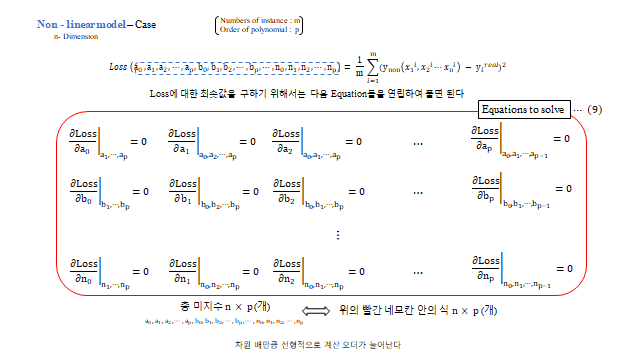
각 \(w\) 는 그 설명변수가 종속변수에 미치는 영향력(가중치)이다. \(m\) 개 데이터(instance)에 대한 연립식을 행렬로 묶으면 깔끔하다.
설명변수가 둘(\(w_1, w_2\))인 경우를 시각화하면, Loss 는 \(w\) 들에 대해 아래로 볼록한 그릇(paraboloid) 모양이 된다. 경사하강법은 이 곡면을 따라 내려가 바닥의 최적점을 찾는 것이다(다차원에서는 \(w_1, w_2, \dots\) 를 동시에 갱신 — Jacobi 방식).
7. 푸는 방법 — 해석적 vs 수치적
Loss 를 최소화하는 \(W\) 를 구하는 길은 둘이다.
- 해석적(Analytical) — 모든 편미분을 0 으로 둔 정규방정식 을 행렬(Gauss elimination)로 직접 푼다. 모델이 다항식이면 가능하지만 차원이 커지면 계산량이 급증한다.
- 수치적(Numerical) — 경사하강법 으로 반복 갱신한다. 실제 모델이 다항식이라는 보장이 없으므로(일반적), 이쪽을 주로 쓴다.
8. 이진 분류와 더미 변수
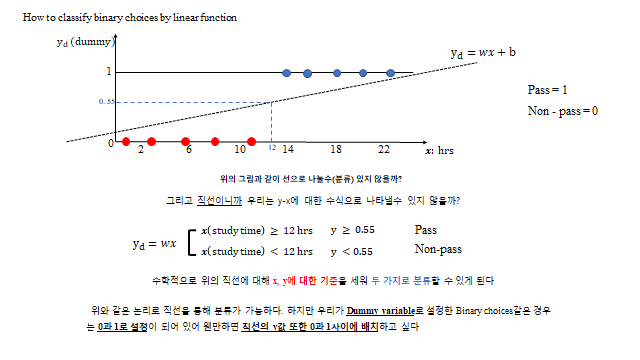
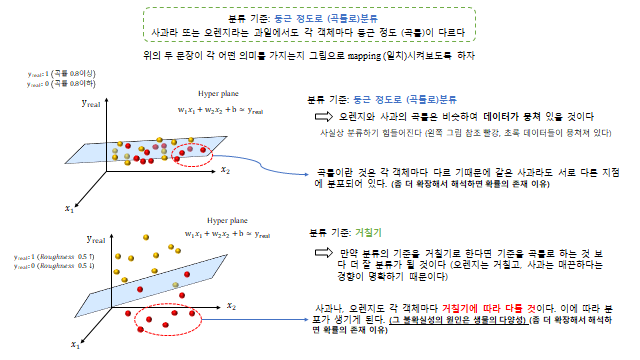
Machine learning 의 다른 목적 중 하나는 Classification(분류) 이다. 어떤 예시가 있을까? Pass or Non-pass, Animal or plants, Spam e-mail or Ham e-mail 처럼 두 가지로 분류할 경우 이것을 Binary classification(이진 분류) 이라 한다. 과연 분류를 위해서는 어떤 논리의 알고리즘을 써야 하는가? 위의 흐름에 의하면 이 의문은 다시 말해 ‘어떤 model 을 이용하면 되겠는가?’ 로 바꿔볼 수 있다. 놀랍게도 여기서도 Linear regression 을 사용 하게 된다.
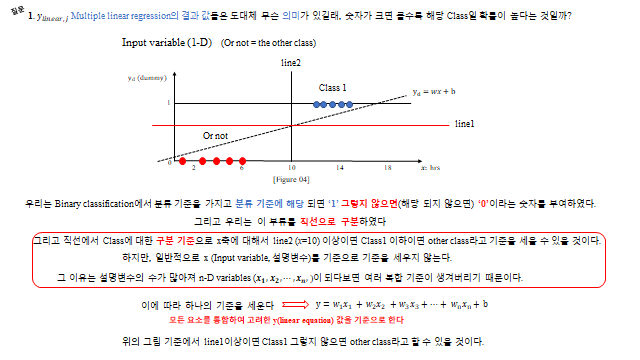
컴퓨터는 Pass, Non-pass 를 인식하지 못한다. 이에 따라 컴퓨터가 알 수 있는 숫자로 알려줘야 한다. 두 가지 경우의 수이므로 1, 0 으로 알려주는데, 이렇게 문자를 의미 있는 숫자로 분류하기 위해 1, 0 으로 알려주는 것을 더미 변수(Dummy variable) 라 한다. (예: Pass=1 / Non-pass=0, Animal=1 / Plant=0, Spam=1 / Ham=0.)
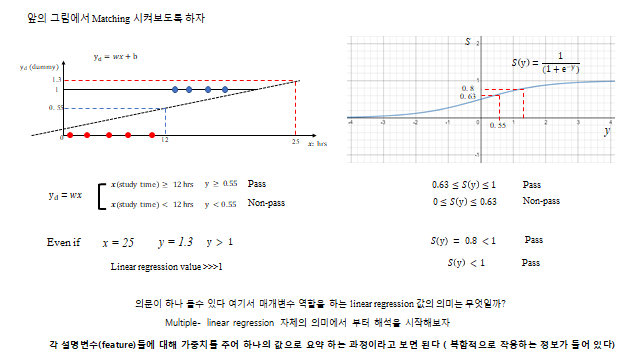
위 그림과 같이 선으로 나눌(분류할) 수 있지 않을까? 그리고 직선이니까 \(y\)–\(x\) 에 대한 수식으로 나타낼 수 있다. 예를 들어 공부 시간 \(x\) 에 대해
처럼 직선에 대해 \(x, y\) 의 기준(임계값)을 세워 두 가지로 분류할 수 있다. 하지만 Dummy variable 로 설정한 Binary choices 는 0 과 1 로 되어 있어, 원한다면 직선의 \(y\) 값 또한 0 과 1 사이에 배치하고 싶다. 그런데 직선 \(y=wx+b\) 는 입력이 커질수록 \(y\) 가 1 을 한참 넘어버린다(예: \(x=25\) 면 \(y=1.3>1\)). 더미 변수는 0~1 사이라야 자연스러운데 말이다.
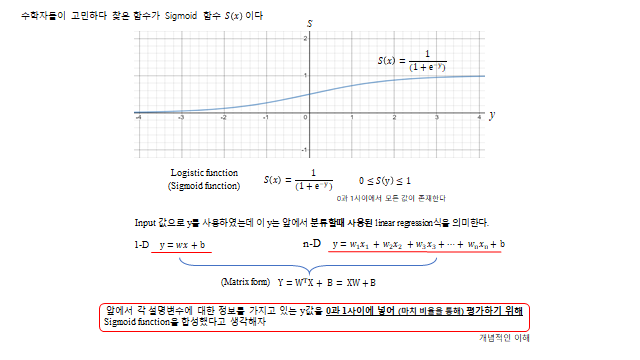
9. 시그모이드와 로지스틱 회귀
그래서 수학자들이 고민하다 찾은 함수가 Sigmoid 함수 \(S(x)\)(Logistic function)다. 어떤 값이든 0 과 1 사이로 눌러 담아 “확률·비율”처럼 다룰 수 있게 한다.
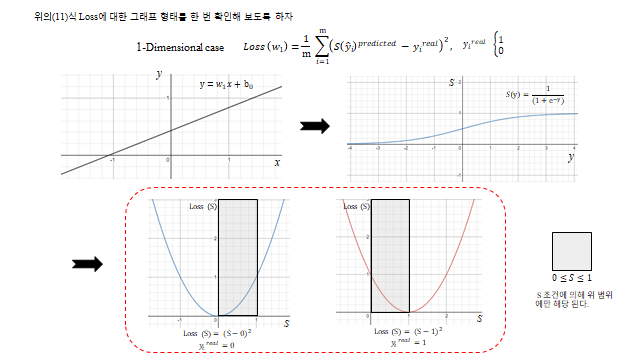
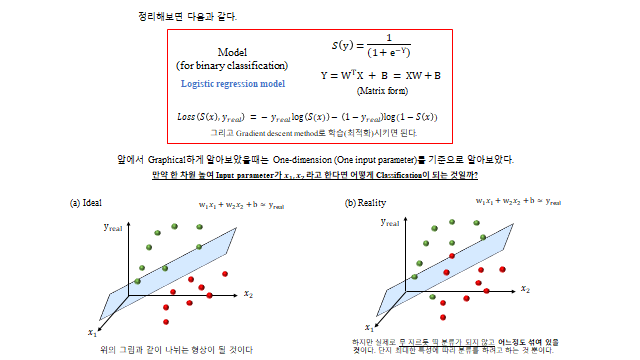
Input 값으로 쓰인 \(y\) 는 앞에서 분류에 사용된 linear regression 을 의미한다. 입력이 하나면 \(y=wx+b\), 여럿이면 \(y=w_1x_1+\cdots+w_nx_n+b\) 이고, 행렬형으로는 \(Y=W^\mathsf{T}X+B=XW+B\) 다. 각 설명변수에 대한 정보를 가진 \(y\) 값을 0 과 1 사이에 넣어(마치 비율을 통해) 평가하기 위해 Sigmoid 를 합성했다고 생각하면 된다. 결론적으로 아래 모델을 Binary classification 목적으로 쓴다.
여기서 \(X\) 는 input variable, \(W\) 는 weight(trainable), \(B\) 는 bias(trainable)다.
10. 교차 엔트로피 손실 (Cross-entropy)
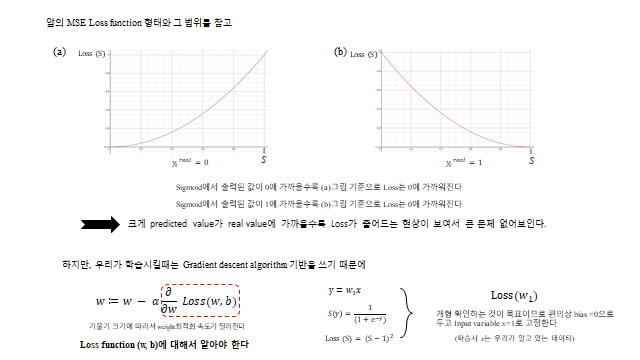
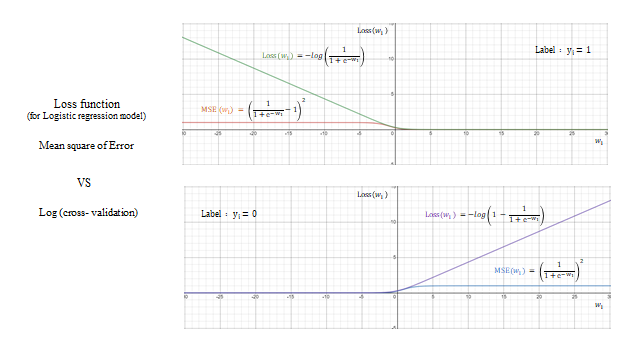
model 을 잡았으니 trainable variable 인 \(W, B\) 를 학습시킬 Loss function 이 필요하다. Logistic regression model 에도 MSE 를 Loss 로 잡으면 어떨까?
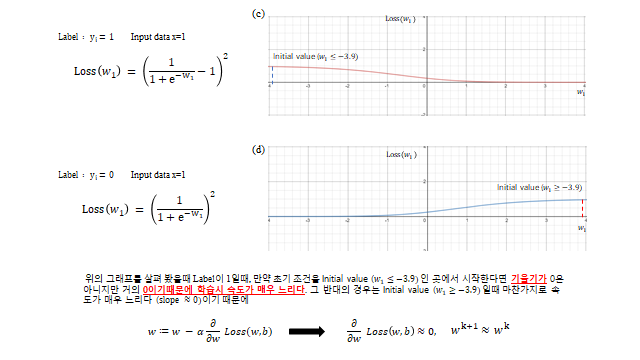
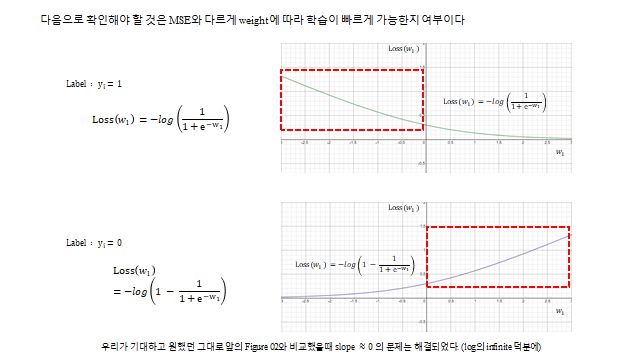
predicted value 가 real value 에 가까워지면 Loss 가 줄어들어 큰 문제 없어 보인다. 하지만 우리가 학습시킬 때는 Gradient descent 기반 을 쓰기 때문에 \(\text{Loss}(w,b)\) 의 기울기 가 중요하다. label \(y_1=1\), input \(x=1\) 일 때 \(\text{Loss}(w_1)=\big(\tfrac{1}{1+e^{-w_1}}-1\big)^2\) 인데, 초기값을 \(w_1 \le -3.9\) 같은 곳에서 시작하면 기울기가 0 에 가까워 학습이 매우 느리다(\(\partial \text{Loss}/\partial w \approx 0 \Rightarrow w^{k+1}\approx w^k\)). 반대 라벨도 마찬가지다. 즉 시그모이드 때문에 slope ≈ 0 인 구간이 생겨 학습이 안 되는 문제가 있다.
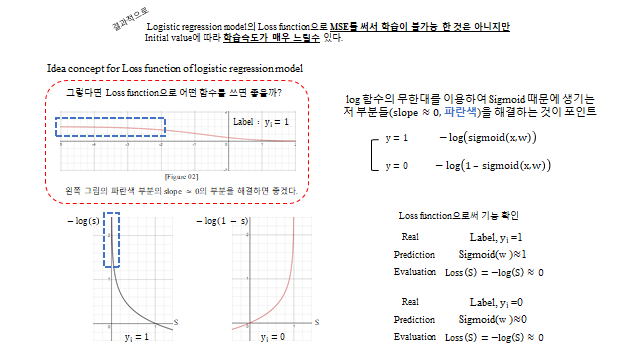
그렇다면 Loss function 으로 어떤 함수를 쓰면 좋을까? log 함수의 무한대 를 이용하여 Sigmoid 때문에 생기는 저 평평한 부분(slope ≈ 0)을 해결하는 것이 포인트다.
기능을 확인해 보면 — 실제 Label \(y=1\) 인데 Prediction \(S(w)\gg 1\)(즉 1에 가까움)이면 \(-\log(S)\approx 0\), 실제 Label \(y=0\) 인데 \(S(w)\approx 0\) 이면 \(-\log(1-S)\approx 0\) 으로 잘 작동한다. 그리고 MSE 와 달리 slope ≈ 0 문제도 log 의 infinite 덕분에 해결 된다. 이렇게 log 로 취한 Loss function 을 cross-entropy 라 부른다.
Label 이 ‘0’ 이냐 ‘1’ 이냐에 따라 cross-entropy 형태가 달라진다. 이것을 하나의 식으로 나타낼 방법이 없을까? 여기서 1 이라는 숫자는 곱하면 자기 자신을 그대로 유지해주고, 0 이라는 숫자는 자기 자신을 없애버리는 성질을 이용한다. \(y_{real}\) 이 1, 0 으로만 이루어지므로 다음 한 식으로 두 경우를 모두 담을 수 있다.
\(y_{real}=1\) 이면 \(-\log S(x)\), \(y_{real}=0\) 이면 \(-\log(1-S(x))\) 가 되어, 앞의 두 경우와 정확히 일치한다.
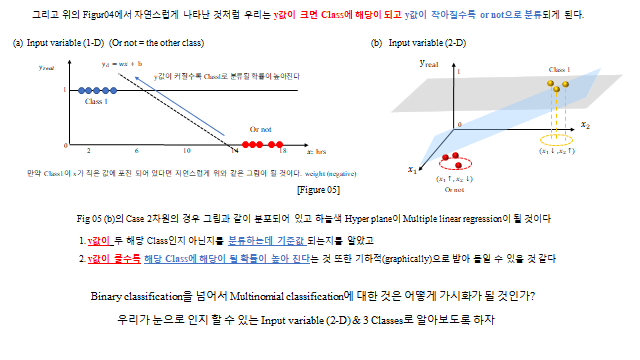
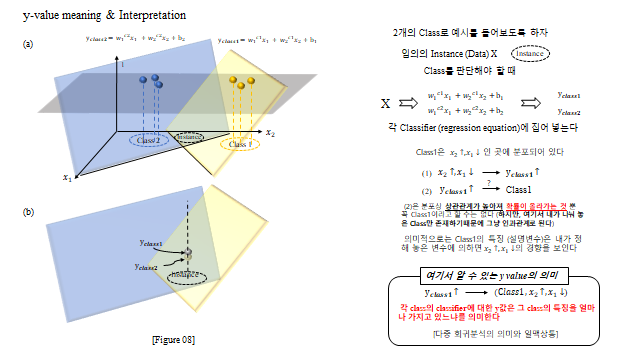
앞에서는 입력이 하나(1-D)인 경우로 보았는데, 한 차원 높여 입력이 \(x_1, x_2\) 라면 분류 경계는 직선이 아니라 평면(Hyperplane) 이 된다 — \(w_1 x_1 + w_2 x_2 + b \approx y_{real}\). \(y\) 값이 클수록 그 클래스에 해당될 확률이 높아진다.
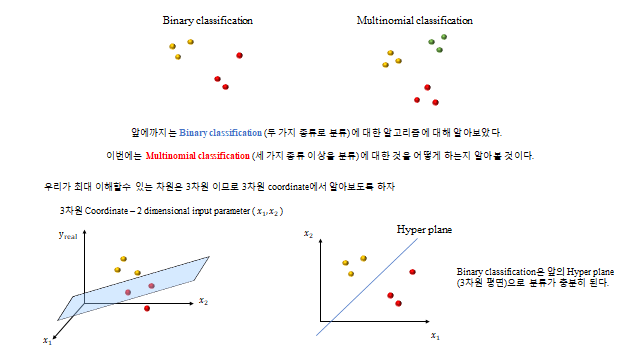
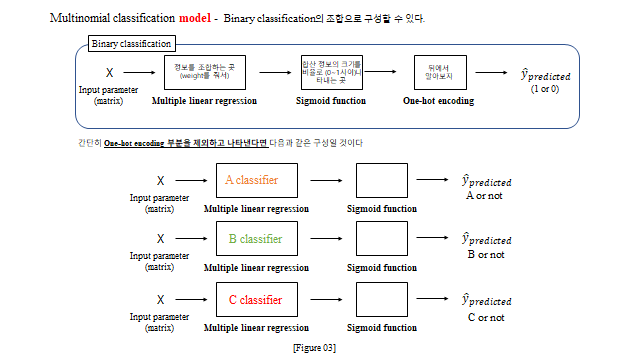
11. 다중 분류 (Multinomial Classification)
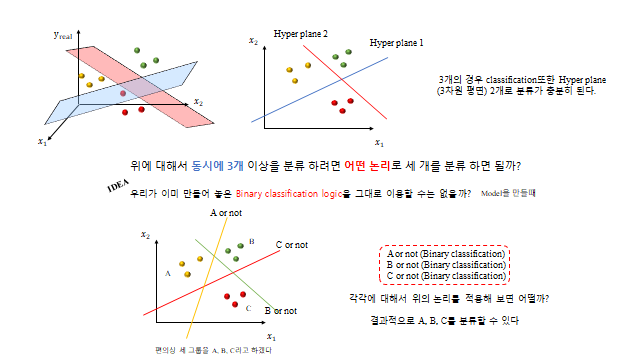
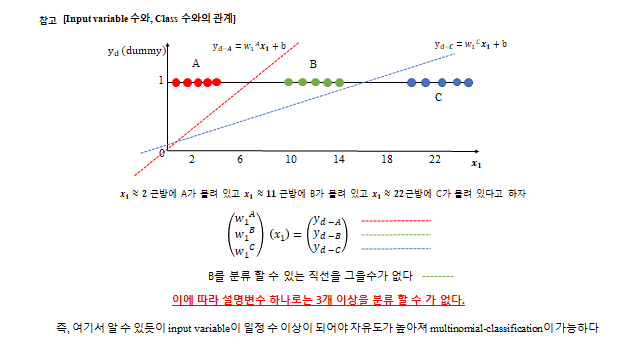
세 종류 이상으로 나누려면 어떻게 할까? 이미 만든 이진 분류 로직을 재사용 한다 — “A냐 아니냐, B냐 아니냐, C냐 아니냐”(One-vs-Rest). 단, 클래스가 많아지면 그만큼 설명변수(자유도)도 충분해야 한다.
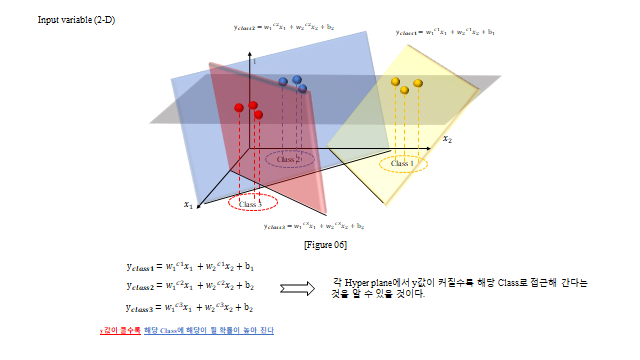
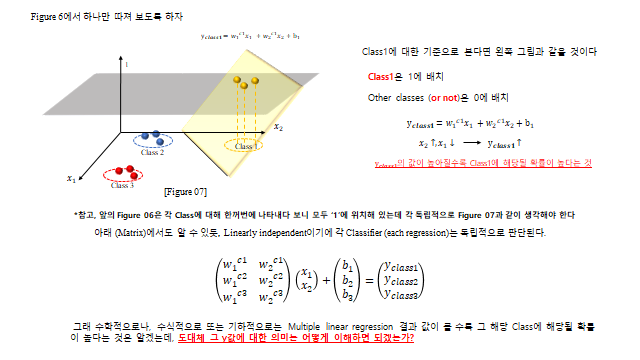
3D 로 보면, 세 클래스는 여러 개의 Hyperplane 으로 나뉜다(각 클래스마다 \(y_{class}=w_1^{c}x_1+w_2^{c}x_2+b\) 평면). 임의의 데이터에 대해 \(y\) 값이 가장 높은 평면의 클래스로 분류한다.
전체 모델은 다음 파이프라인이다.
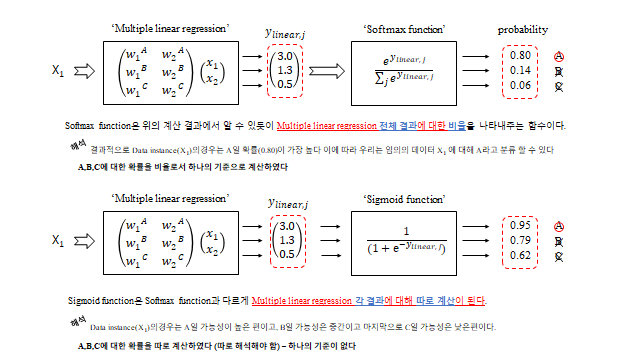
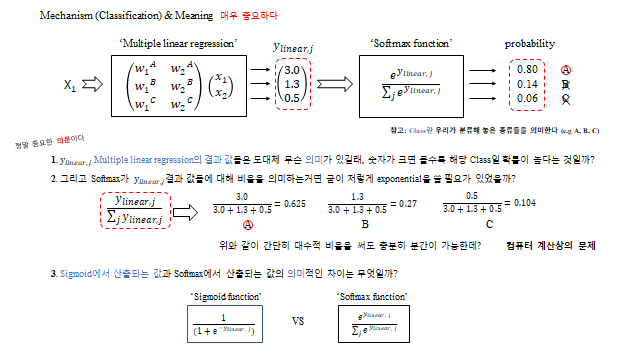
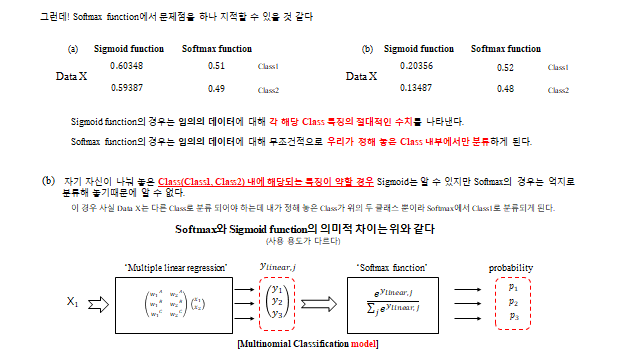
12. Softmax vs Sigmoid
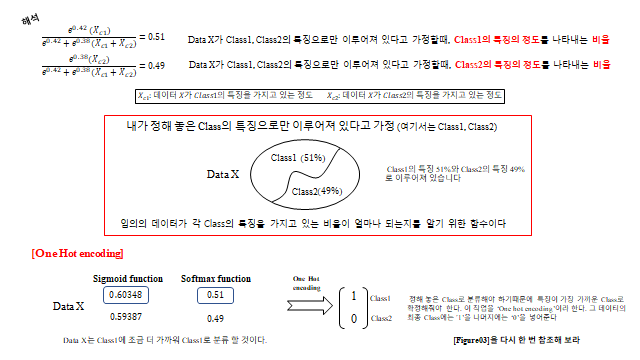
다중 분류에서는 시그모이드 대신 Softmax 를 자주 쓴다. 둘 다 \(0\sim1\) 값을 주지만 의미가 다르다.
- Softmax — 정해 놓은 클래스들 안에서의 비율(합 = 1). 무조건 그 안에서 분류된다.
- Sigmoid — 각 클래스 특징의 절대적 정도(서로 독립). 어디에도 해당 안 되면 모두 낮게 나온다.
최종적으로 가장 큰 확률의 클래스를 1, 나머지를 0 으로 만드는 것이 One-hot encoding 이다. 다중 분류의 Loss 는 각 클래스의 교차 엔트로피를 클래스·데이터에 대해 모두 더한 것이다.
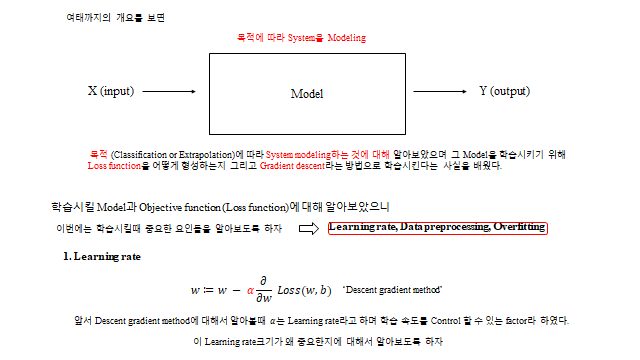
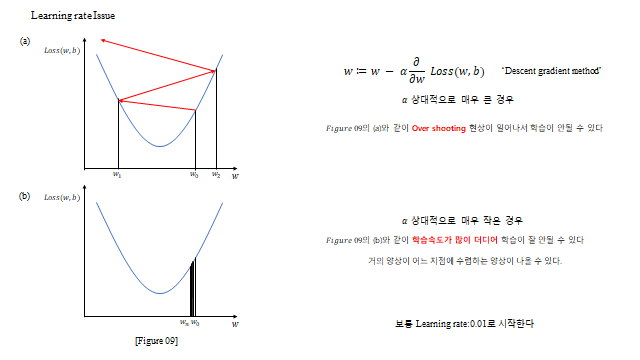
13. 학습률 (Learning rate)
경사하강의 보폭 \(\alpha\) 가 학습 속도를 좌우한다. 너무 크면 골짜기를 넘나드는 overshooting 으로 발산하고, 너무 작으면 학습이 한없이 느리다. 보통 \(0.01\) 정도로 시작한다.
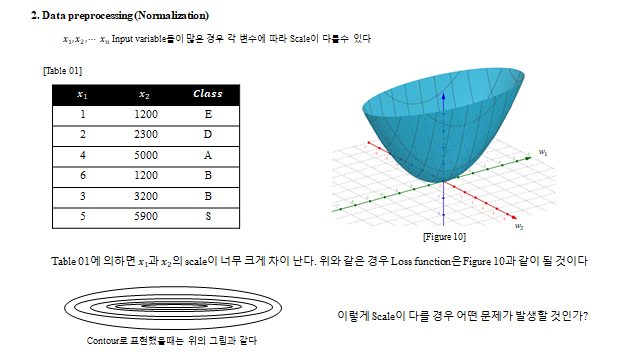
14. 정규화·전처리 (Normalization)
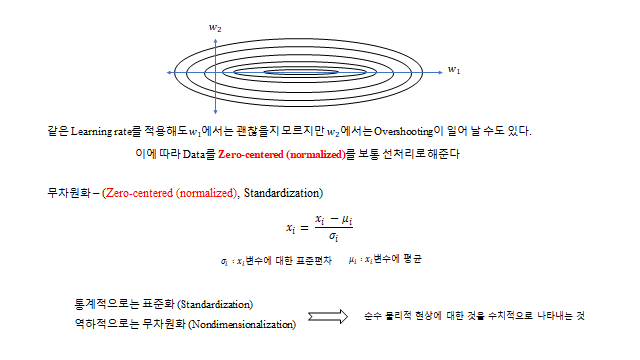
설명변수들의 스케일이 크게 다르면(예: \(x_1\sim\) 한 자리, \(x_2\sim\) 수천), Loss 등고선이 길쭉한 타원이 되어 한쪽 방향에서 overshooting 이 난다. 그래서 데이터를 표준화(zero-centered) 해 준다.
통계적으로는 표준화(Standardization), 역학적으로는 무차원화(Nondimensionalization)와 같은 개념이다.
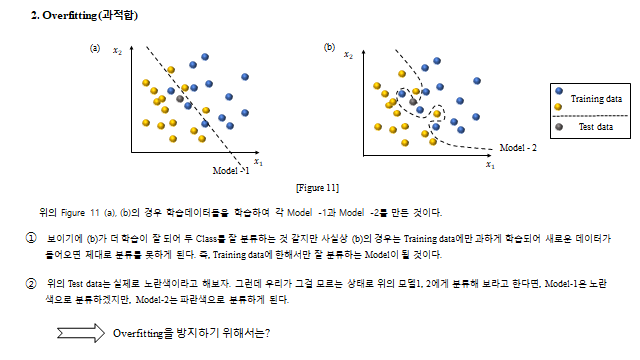
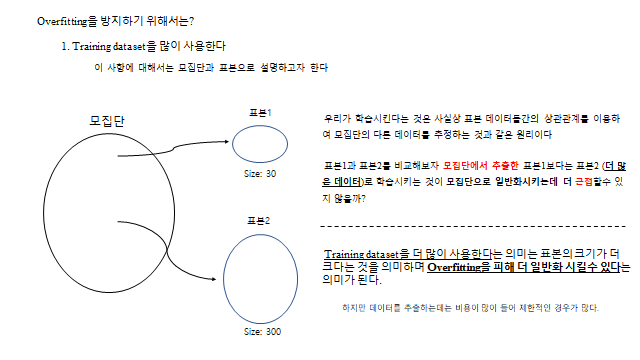
15. 과적합 (Overfitting)
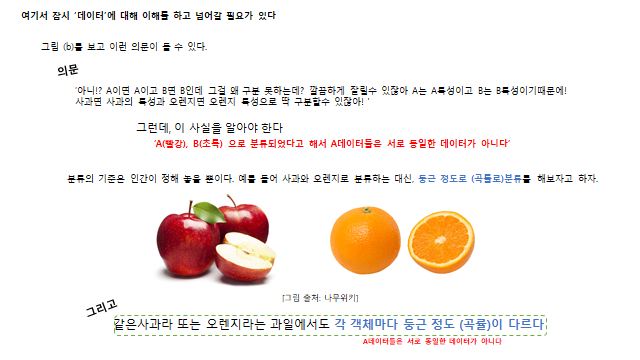
모델이 학습 데이터에만 지나치게 맞춰지면, 새로운(test) 데이터에서는 오히려 틀린다. 아래에서 Model-2 는 학습 데이터를 완벽히 나누지만 과적합되어 일반화에 실패한다.
과적합을 막는 방법은 셋이다.
- ① 학습 데이터를 늘린다 — 표본이 클수록 모집단을 잘 일반화한다 (단, 수집 비용↑).
- ② 변수(feature) 수를 줄인다 — 종속변수를 잘 설명하는 변수만 남긴다 (상관 과다·무관 변수 제거, AIC·BIC·VIF).
- ③ Regularization(정규화) — Loss 에 가중치 크기 벌점을 더해 모델을 단순하게 유지한다.
16. 데이터셋 분할 & 평가
과적합 여부와 학습 상태를 확인하려고 전체 데이터를 Training / Validation / Test 로 나눈다.
Training 으로 학습하며 Validation 으로 모의 평가하고, 마지막에 한 번 Test 로 최종 성능을 본다. 모델 정확도(Accuracy)는 목적에 따라 다르게 측정한다.
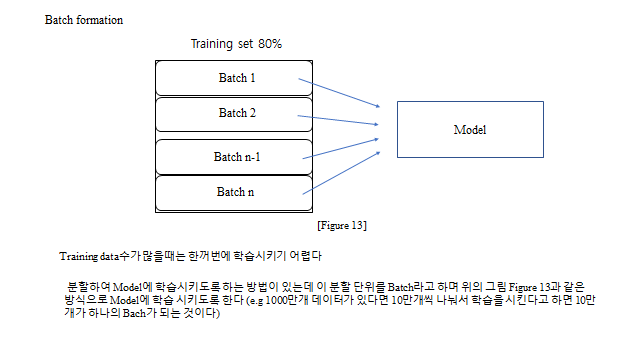
데이터가 많으면 한 번에 학습하기 어려우므로 Batch 단위로 나눠 학습시킨다(예: 1000만 개를 10만 개씩 100 배치). 정리하면, 머신러닝은 목적에 맞는 모델과 Loss 를 세우고 → 경사하강으로 최적화하며 → 학습률·정규화·과적합을 관리 하는 과정이다.
원본 PPT 슬라이드 보기






















📑 위 슬라이드는 제가 대학원 시절(2020) 머신러닝을 직접 공부하며 만들고 정리한 발표·학습 자료입니다.