강화학습 (Reinforcement Learning)
강화학습을 MDP(Markov Decision Process) 관점에서 바닥부터 정리한 글이다. 한 줄기로 꿰면 — 5가지 요소 → Markov Process → MDP → 가치함수(V, Q)와 Bellman 방정식 → (모델 기반) Dynamic Programming → (모델 free) Monte-Carlo · Temporal Difference → SARSA · Q-learning.
한 줄 정의 — 사람은 주변 환경(사회·자연) 속에서 경험을 통해 자신의 이득(보상)이 되는 방향으로 행동을 학습한다. 강화학습은 이 메커니즘을 그대로 알고리즘으로 옮긴 것이다. Agent 가 Environment 속에서 보상을 최대화하는 정책(Policy) 을 찾는 것이 목표다.
1. 강화학습의 5가지 요소
위 문장에서 알고리즘에 필요한 개념을 뽑으면 다섯 가지다.
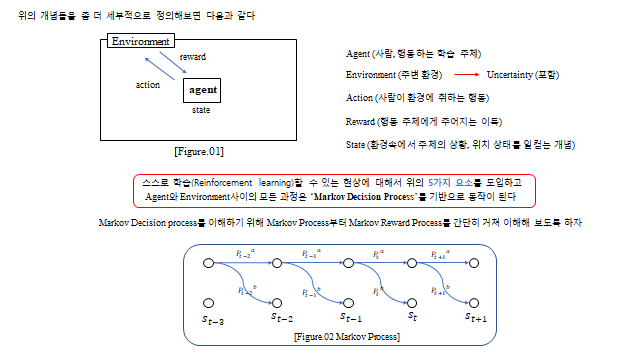
- Agent — 행동하는 학습 주체 (사람)
- Environment — 주변 환경 (불확실성, uncertainty 을 포함)
- Action — Agent 가 환경에 취하는 행동
- Reward — 행동 주체에게 주어지는 이득(보상)
- State — 환경 속 주체의 상황·위치 상태
2. Markov Process → MRP → MDP
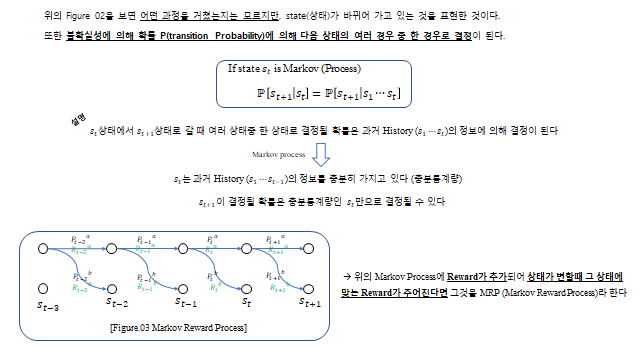
강화학습의 토대는 Markov Process 다. 다음 상태가 과거 전체 history 가 아니라 현재 상태만 으로 결정된다는 성질(Markov property)이다.
여기에 단계별로 개념을 쌓는다.
- Markov Process (MP) — 상태 전이 \(P\) 만 있는 과정
- Markov Reward Process (MRP) — 상태 변화에 따른 Reward 추가
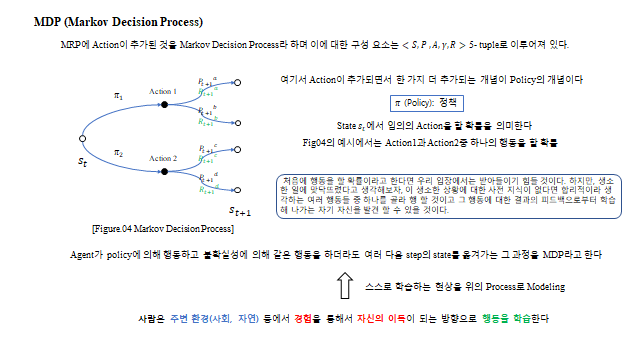
- Markov Decision Process (MDP) — Action 까지 추가. 5-tuple \(\langle S, P, A, \gamma, R\rangle\). 상태 \(s_t\) 에서 행동을 고를 확률 = 정책(Policy) \(\pi\)
3. 가치함수 — State value · Action value · Return
목적을 가지고 행동하며 보상을 최대화하려면, “어떤 상태/행동이 얼마나 좋은가”를 수치화해야 한다. 두 가지 가치함수가 도입된다.
- State value function \(V(s)\) — 각 상태의 가치
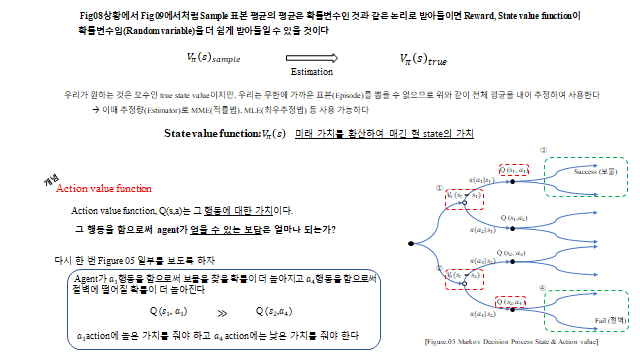
- Action value function \(Q(s,a)\) — 어떤 상태에서 특정 행동을 했을 때의 가치
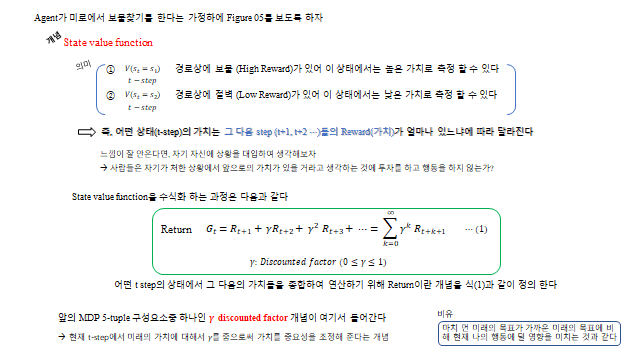
현재 상태의 가치는 “그 다음 step 들의 Reward 가 얼마나 있느냐”에 달려 있다. 미래 보상을 종합하는 개념이 Return \(G_t\) 이며, 가까운 미래에 가중치를 주기 위해 할인율(discounted factor) \(\gamma\in[0,1]\) 을 쓴다.
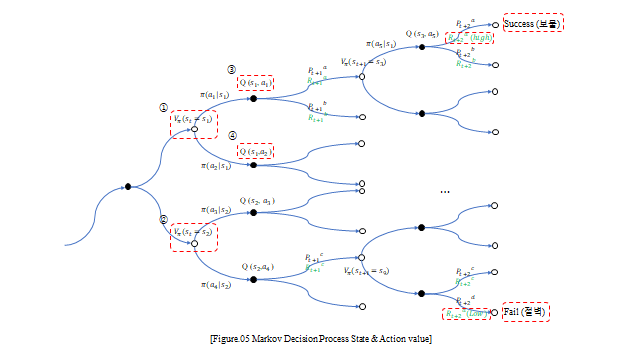
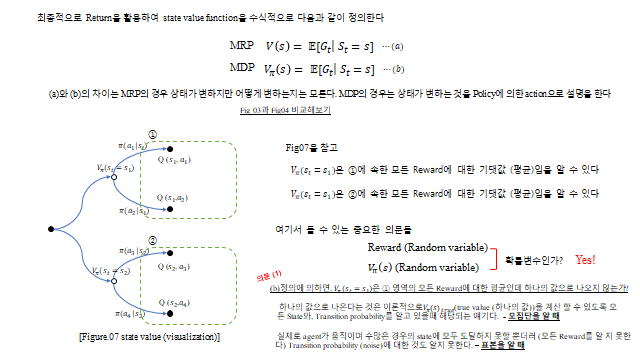
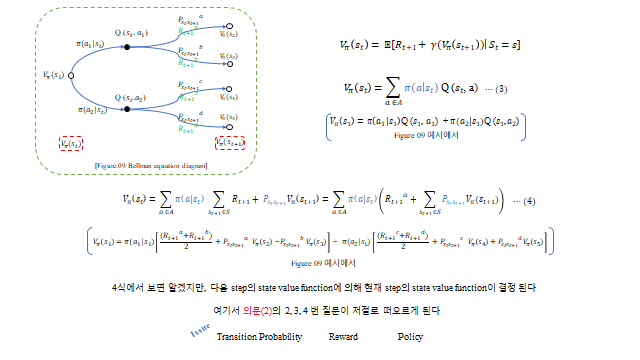
상태 \(s_t\) 에서 정책 \(\pi(a\mid s)\) 로 행동을 고르고, 그 행동마다 전이확률 \(P\) 와 보상 \(R\) 로 다음 상태가 갈라진다. 이렇게 펼치면 아래와 같은 트리(tree) 가 되고, 경로 끝에는 Success(보상)·Fail(벌점)이 있다. \(V_\pi(s)\) 는 그 상태에서 갈 수 있는 모든 Reward 의 기댓값, \(Q_\pi(s,a)\) 는 특정 행동을 했을 때의 기댓값이다.
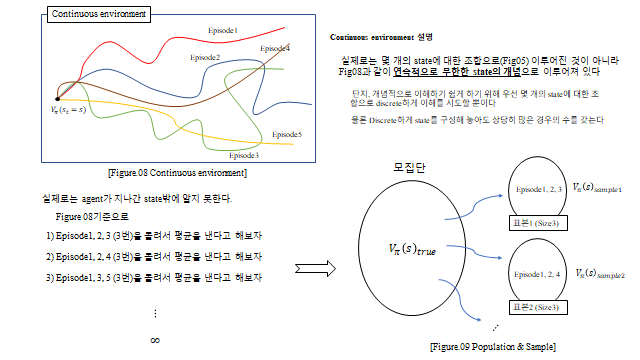
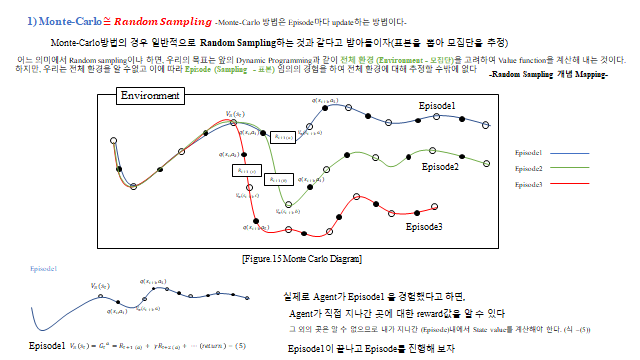
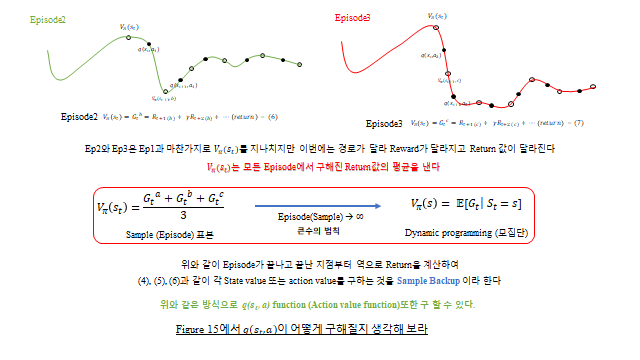
중요한 점 — Reward 와 가치함수는 환경의 불확실성(transition probability) 때문에 확률변수(random variable) 다. 그래서 실제로는 참값 \(V_\pi(s)_{true}\) 를 알 수 없고, 여러 표본(Episode) 의 평균으로 추정 한다(모집단 vs 표본).
4. Bellman 기대 방정식
Return 은 무한급수처럼 보이지만, 핵심은 현재 상태의 가치가 “다음 step 의 Reward + 다음 상태의 가치”로 재귀적으로 결정 된다는 것이다. 가치함수의 정의에서 출발해 Return 을 한 step 분리하면 자기 자신이 다시 나타난다.
마지막 줄이 Bellman expectation equation 이다 — 무한급수가 “바로 다음 보상 + 할인된 다음 상태의 가치”라는 한 step 재귀로 접힌다.
정책과 전이확률로 펼치면, \(V\) 와 \(Q\) 의 관계로도 쓸 수 있다.
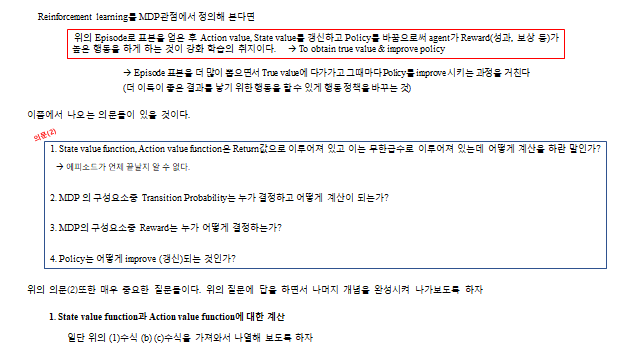
기댓값(평균)을 계산하려면 확률적 요소인 Transition probability 와 Policy 를 알아야 한다 — 여기서 네 가지 의문이 생긴다.
① 가치함수 는 무한급수인데 어떻게 계산하나? ② Transition probability 는 누가 정하나(=환경의 noise·불확실성, pdf 로 존재하지만 우리는 모름)? ③ Reward 는 누가 정하나(=우리가 agent 에게 설계해 주는 reward rule)? ④ Policy 는 어떻게 개선(update)하나?
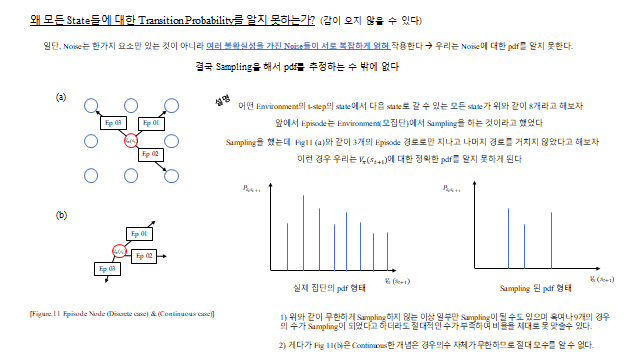
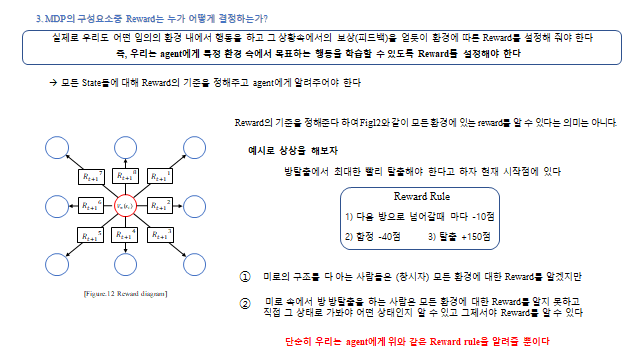
Transition probability 는 환경 안의 noise(불확실성)다. 같은 행동을 해도 여러 case 의 state 로 나뉜다 — 예를 들어 30N 의 힘으로 비행기를 날리는데 주변 바람(noise)에 의해 3m 갈 수도, 4m 갈 수도, 2m 갈 수도 있다. 즉 Transition probability 는 우리가 모르는 어떤 확률분포(pdf)로 존재하며, 결국 표본(Sampling)으로 추정 할 수밖에 없다. Reward 는 우리가 agent 에게 설계해 알려주는 reward rule 이다. 아래 미로 예시처럼 “다음 방으로 넘어갈 때마다 −10, 함정 −40, 탈출 +150” 같은 규칙을 준다.
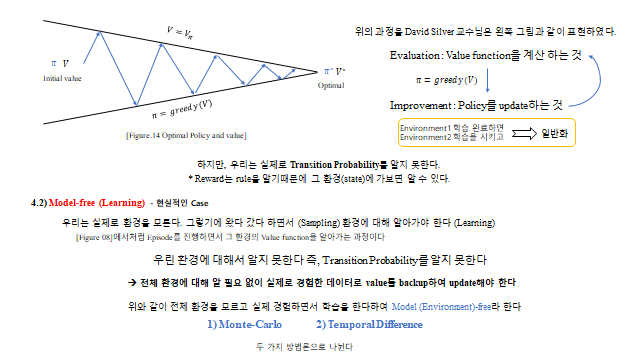
5. 모델 기반 — Dynamic Programming & Policy Iteration
먼저 이상적인 경우. 환경(전이확률·Reward)을 전부 안다 고 가정하면, Bellman 방정식을 반복 적용해 가치를 채워 나갈 수 있다(Dynamic Programming / Planning). 환경의 모든 상태를 훑어 계산하므로 full-width backup 이라 부른다.
- Policy 를 임의로 설정(균등 확률)
- \(V_\pi(s)\) 를 임의 값(보통 0)으로 초기화
- Bellman 방정식을 iterative 하게 적용해 \(V_\pi(s)\) 를 수렴시킴 (Evaluation)
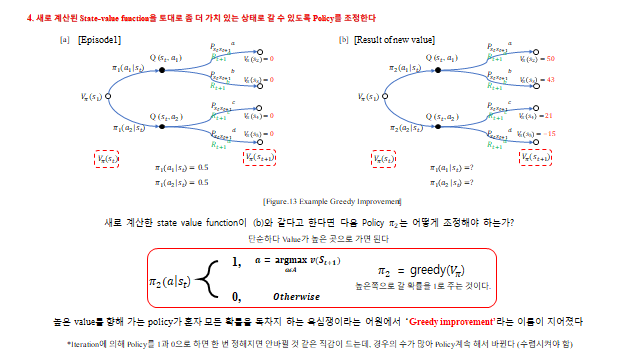
- 새로 계산된 가치를 토대로 가치가 높은 쪽으로 Policy 를 조정 (Improvement, greedy)
6. 모델 free — Monte-Carlo
현실에서는 환경(전이확률)을 모른다. 그래서 전체를 계산하는 대신 실제 경험한 데이터로 value 를 backup 해 업데이트한다(model-free). 첫 번째 방법이 Monte-Carlo(MC) 다.
MC 는 Episode 마다 random sampling 으로 경로를 끝까지 진행한 뒤, 그 Return \(G_t\) 들의 평균으로 가치를 추정한다. 매번 평균을 다시 구하지 않도록 incremental(점증) 형태 로 쓴다.
\(N\) 번째 Episode 까지의 평균은 \(N\)−1 번째까지의 평균(=기존 추정값)으로 다시 쓸 수 있다. \(N\) 번째 Return 만 새로 분리하면 다음과 같이 점증 형태가 나온다.
즉 매번 전체 평균을 다시 구하지 않고 “기존 추정값 + (새 Episode 의 Return − 기존 추정값)의 일부”로 갱신한다.
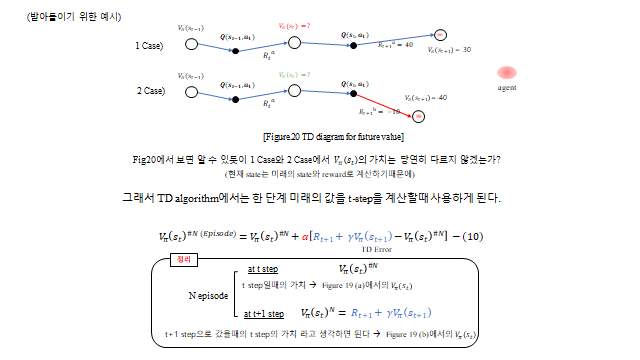
\(\tfrac{1}{N}\) 을 일반적인 학습률 \(\alpha\) 로 바꿔 쓰면 \(V(s_t)\leftarrow V(s_t)+\alpha\,[\,G_t-V(s_t)\,]\) 가 된다. 여기서 “전체 Return \(G_t\)” 대신 “한 step 추정 \(R_{t+1}+\gamma V(s_{t+1})\)”을 넣으면 바로 다음 절의 TD 가 된다.
7. 모델 free — Temporal Difference
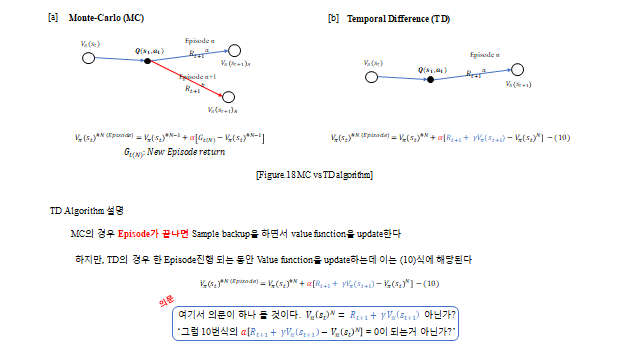
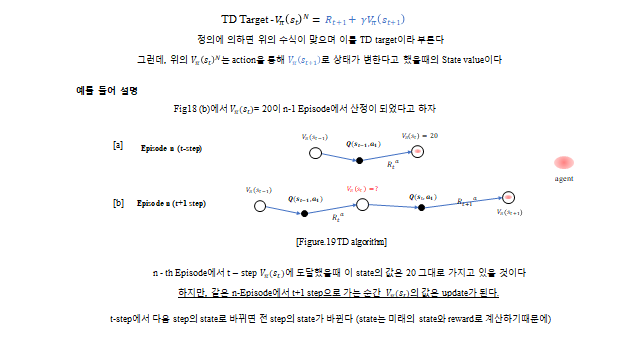
MC 가 Episode 가 끝나야 업데이트한다면, Temporal Difference(TD) 는 Episode 안에서 매 time step 마다 업데이트한다. 다음 한 step 의 추정값으로 현재를 갱신하는 것(bootstrapping)이다.
대괄호 안이 TD error 다. 한 단계 미래의 값(\(R_{t+1}+\gamma V(s_{t+1})\))으로 현재 값을 보정한다. \(\alpha\) 는 가치를 업데이트할 때의 속도를 조절하는 학습률(learning rate) 이다.
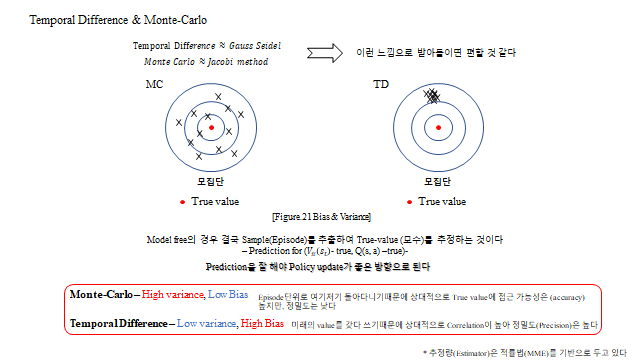
8. MC vs TD — 편향과 분산
두 방법은 모두 참값(true value)을 추정하지만 성격이 다르다. MC 는 Episode 전체 Return 을 쓰기에 분산이 크고 편향은 작다(정확도, accuracy). TD 는 한 step 의 추정을 쓰기에 분산이 작고 편향은 크다(정밀도, precision).
비유하면 MC 는 Jacobi method, TD 는 Gauss–Seidel method 에 가깝다. 실제로는 MC 기반 위에 매 Episode 마다 TD 로 step 업데이트를 더해 둘을 함께 쓴다.
9. Control — ε-greedy 와 SARSA
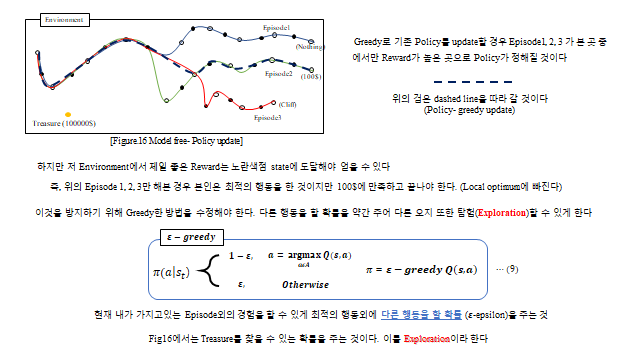
가치를 평가(Prediction)했다면 이제 Policy 를 갱신(Control)해야 한다. 그런데 model-free 에서는 greedy 만 쓰면 탐험(Exploration) 이 부족해 가본 길만 가게 되어 지역 최적(local optimum)에 빠진다. 그래서 일정 확률 \(\varepsilon\) 로 다른 행동도 시도하는 ε-greedy 를 쓴다.
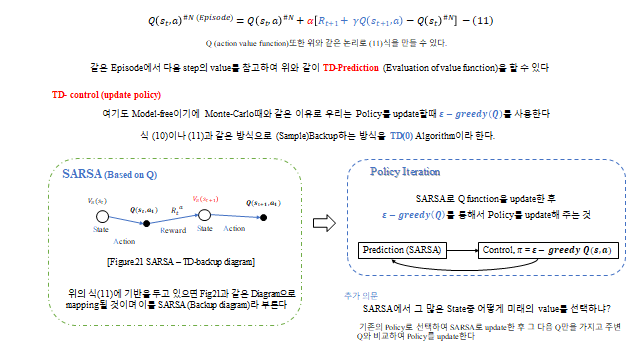
또한 model-free 에서는 \(V\) 가 아니라 \(Q\)(action value) 로 Policy 를 갱신한다. greedy(\(V\)) 를 쓰려면 전이확률(TP)이 필요한데 우리는 그것을 모르기 때문이다. \(Q\) 는 행동까지 포함하므로 TP 없이 바로 행동을 고를 수 있다.
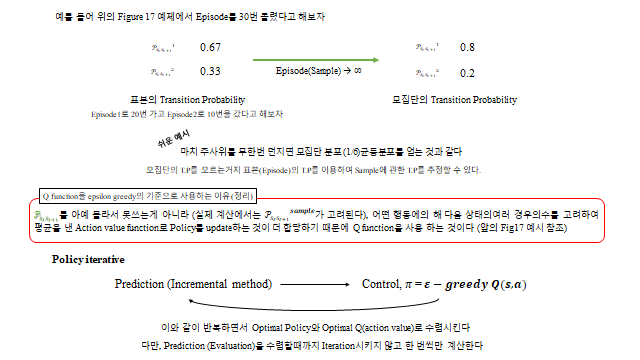
TD 기반으로 \(Q\) 를 갱신하는 대표 알고리즘이 SARSA(on-policy)다. Prediction(SARSA) ⇄ Control(ε-greedy Q) 의 Policy Iteration 으로 최적에 수렴한다.
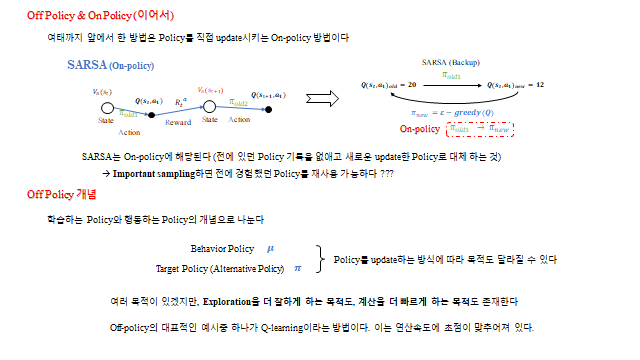
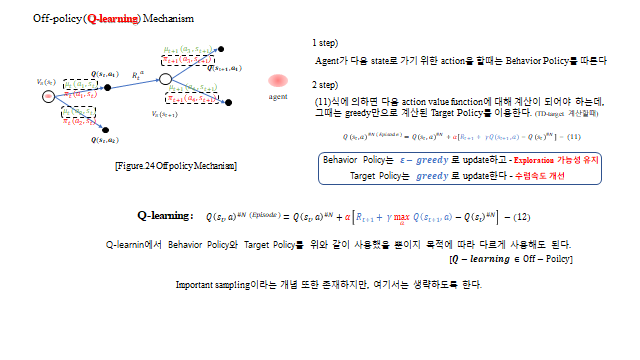
10. Off-policy 와 Q-learning
SARSA 같은 on-policy 는 행동에 쓰는 정책과 학습하는 정책이 같아, ε-greedy 의 탐험 때문에 수렴 속도가 느리다. 이를 보완한 것이 off-policy — 행동하는 정책과 학습하는 정책을 분리한다.
- Behavior Policy \(\mu\) — 실제 행동 (ε-greedy, 탐험 담당)
- Target Policy \(\pi\) — 학습·개선 대상 (greedy, 수렴 속도 개선)
대표적인 off-policy 가 Q-learning 이다. 다음 상태에서 실제 한 행동이 아니라 가능한 최선의 행동(\(\max\))으로 target 을 계산한다.
행동은 Behavior policy(ε-greedy)로 탐험하면서, 학습 target 은 greedy(\(\max\))로 잡아 연산 속도와 수렴을 함께 잡는다.
11. 정리
강화학습은 결국 Environment·Agent 의 학습 요소를 MDP 로 모델링 하고, 가치(Value)를 Prediction(얼마나 좋은가) 한 뒤 Policy 를 Control(어떻게 개선) 하는 과정이다. 환경을 알면 Dynamic Programming, 모르면 Monte-Carlo · Temporal Difference 로 경험에서 backup 하며, 탐험을 위해 ε-greedy 를, 수렴을 위해 off-policy(Q-learning)를 쓴다.
원본 PPT 슬라이드 보기
















📑 위 슬라이드는 제가 대학원 시절 강화학습을 직접 공부하며 만들고 정리한 발표 자료입니다.